Как найти цикл в графе
Содержание
- Алгоритм
- Реализация
- Содержание
- Пример [ править | править код ]
- Определения [ править | править код ]
- Представление в компьютере [ править | править код ]
- Алгоритмы [ править | править код ]
- Черепаха и заяц [ править | править код ]
- Алгоритм Брента [ править | править код ]
- Время в обмен на память [ править | править код ]
- Приложения [ править | править код ]
- Содержание
- Алгоритм [ править ]
- Доказательство [ править ]
Пусть дан ориентированный или неориентированный граф без петель и кратных рёбер. Требуется проверить, является ли он ациклическим, а если не является, то найти любой цикл.
Решим эту задачу с помощью поиска в глубину за O (M).
Алгоритм
Произведём серию поисков в глубину в графе. Т.е. из каждой вершины, в которую мы ещё ни разу не приходили, запустим поиск в глубину, который при входе в вершину будет красить её в серый цвет, а при выходе — в чёрный. И если поиск в глубину пытается пойти в серую вершину, то это означает, что мы нашли цикл (если граф неориентированный, то случаи, когда поиск в глубину из какой-то вершины пытается пойти в предка, не считаются).
Сам цикл можно восстановить проходом по массиву предков.
Реализация
Здесь приведена реализация для случая ориентированного графа.
Для любой функции f , отображающей конечное множество S в себя, и для любого начального значения x из S последовательность итеративных значений функции
x 0 , x 1 = f ( x 0 ) , x 2 = f ( x 1 ) , … , x i = f ( x i − 1 ) , … <displaystyle x_<0>, x_<1>=f(x_<0>), x_<2>=f(x_<1>), dots , x_=f(x_), dots >
должна, в конечном счёте, использовать одно значение дважды, то есть должна существовать такая пара индексов i и j , что xi = xj . Как только это случится, последовательность будет продолжаться периодически [en] , повторяя ту же самую последовательность значений от xi до xj − 1 . Нахождение цикла — это задача поиска индексов i и j при заданной функции f и начальном значении x .
Известно несколько алгоритмов поиска цикла быстро и при малой памяти. Алгоритм «черепахи и зайца» Флойда передвигает два указателя с различной скоростью через последовательность значений, пока не получит одинаковые значения. Другой алгоритм, алгоритм Брента, основан на идее экспоненциального поиска [en] . Оба алгоритма, Флойда и Брента, используют только фиксированное число ячеек памяти, и число вычислений функции пропорционально расстоянию от стартовой точки до первой точки повторения. Некоторые другие алгоритмы используют большее количество памяти, чтобы получить меньшее число вычислений значений функции.
Задача нахождения цикла используется для проверки качества генераторов псевдослучайных чисел и криптографических хеш-функций, в алгоритмах вычислительной теории чисел [en] , для определения бесконечных циклов в компьютерных программах и периодических конфигураций клеточных автоматов, а также для автоматического анализа формы [en] связных списков.
Содержание
Пример [ править | править код ]

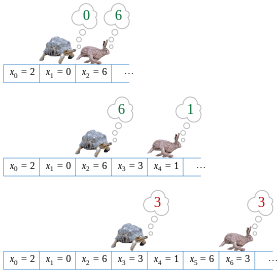
Рисунок показывает функцию f , отображающую множество S = <0,1,2,3,4,5,6,7,8 >на себя. Если начать с точки x = 2 и повторять применение функции f к получаемым значениям, увидим последовательность значений
2, 0, 6, 3, 1, 6, 3, 1, 6, 3, 1, .
Цикл в этой последовательности значений — 6, 3, 1 .
Определения [ править | править код ]
Пусть S — конечное множество, f — некая функция, отображающая S в то же самое множество, а x — любой элемент из S . Для любого i > 0 пусть xi = f(xi − 1) . Пусть μ — наименьший индекс, для которого значение xμ повторяется бесконечное число раз в последовательности значений xi , и пусть λ (длина цикла) — наименьшее положительное целое число, такое, что xμ = xλ + μ . Задача нахождения цикла — это задача поиска λ и μ [1] .
Можно рассматривать эту задачу как задачу теории графов, если построить функциональный граф (то есть ориентированный граф, в котором каждая вершина имеет единственную исходящую дугу), вершины которого являются элементами множества S , а рёбра соответствуют отображению элементов в соответствующие значения функции, как показано на рисунке. Множество вершин, достижимых [en] * из стартовой вершины x образуют подграф в форме, похожем на греческую букву ро ( ρ ) — путь длины μ от x до цикла из λ вершин [2] .
Представление в компьютере [ править | править код ]
Обычно f не задаётся в виде таблицы значений, как показано на рисунке выше. Скорее алгоритм определения цикла может получить на входе либо последовательность значений xi , либо подпрограмму вычисления f . Задача состоит в нахождении λ и μ с проверкой малого числа значений последовательности, либо с обращением к процедуре вычисления значения как можно меньшее число раз. Обычно важна также ёмкостная сложность [en] алгоритма задачи нахождения цикла: желательно использовать память, значительно меньшую по сравнению с размером последовательности целиком.
В некоторых приложениях, и, в частности, в ро-алгоритме Полларда для факторизации целых чисел, алгоритм имеет очень ограниченный доступ к S и f . В ро-алгоритме Полларда, например, S — это множество сравнимых по неизвестному простому множителю числа, который следует разложить на множители, так что даже размер множества S для алгоритма неизвестен. Чтобы алгоритм нахождения цикла работал в таких стеснённых условиях, он должен разрабатываться на основе следующих возможностей. Первоначально алгоритм имеет в памяти объект, представляющий указатель на начальное значение x . На любом шаге алгоритм может осуществлять одну из трёх действий: он может копировать любой указатель в любой другой объект памяти, он может вычислить значение f и заменить любой указатель на указатель на вновь образованный объект из последовательности, или использовать процедуру проверки совпадения значений, на которые указывают два указателя.
Тест проверки равенства может повлечь некоторые нетривиальные вычисления. Например, в ро-алгоритме Полларда этот тест проверяет, не имеет ли разность двух запомненных значений нетривиальный наибольший общий делитель с разлагаемым на множители числом [2] . В этом контексте, по аналогии с моделью вычисления машины указателей [en] , алгоритм, использующий только копирование указателей, передвижение в последовательности и тест на равенство, можно назвать алгоритмом указaтелей.
Алгоритмы [ править | править код ]
Если вход задан как подпрограмма вычисления f , задачу нахождения цикла можно тривиально решить, сделав только λ + μ вызовов функции просто путём вычисления последовательности значений xi и использования структуры данных такой, как хеш-таблица, для запоминания этих значений и теста, что каждое последующее значение ещё не запомнено. Однако ёмкостная сложность данного алгоритма пропорциональна λ + μ , и эта сложность излишне велика. Кроме того, чтобы использовать этот метод для алгоритма указателей, потребуется использовать тест на равенство для каждой пары значений, что приведёт к квадратичному времени. Таким образом, исследования в этой области преследуют две цели: использовать меньше места, чем этот бесхитростный алгоритм, и найти алгоритм указателей, который использует меньше проверок на равенство.
Черепаха и заяц [ править | править код ]
Алгоритм Флойда поиска цикла — это алгоритм указателей, который использует только два указателя, которые передвигаются вдоль последовательности с разными скоростями. Алгоритм называется также алгоритмом «черепахи и зайца» с намёком на басню Эзопа «Черепаха и заяц» [en] .
Алгоритм назван именем Роберта Флойда, которому Дональд Кнут приписывает изобретение метода [3] [4] . Однако алгоритм не был опубликован в работах Флойда, и, возможно, это ошибка атрибуции: Флойд описывает алгоритмы для перечисления всех простых циклов в ориентированном графе в статье 1967 года [5] , но в этой статье не описана задача нахождения цикла в функциональных графах, являющихся объектами рассмотрения статьи. Фактически утверждение Кнута, сделанное в 1969 году и приписывающее алгоритм Флойду без цитирования, является первым известным упоминанием данного алгоритма в печати, и, таким образом, алгоритм может оказаться математическим фольклором [en] , не принадлежащим определённой личности [6] .
Основная идея алгоритма заключается в том, что для любых целых i ≥ μ и k ≥ 0 , xi = xi + kλ , где λ — длина цикла, а μ — индекс первого элемента в цикле. В частности, i = kλ ≥ μ тогда и только тогда, когда xi = x2i .
Таким образом, чтобы найти период ν повторения, который будет кратен λ , алгоритму нужно проверять на повторение лишь значения этого специального вида — одно значение вдвое дальше от начала, чем второе.
Как только период ν будет найден, алгоритм пересматривает последовательность с начальной точки, чтобы найти первое повторяющееся значение xμ в последовательности, используя факт, что λ делит ν , а потому xμ = xμ + v . Наконец, как только значение μ станет известно, легко найти длину λ кратчайшего цикла повторения путём нахождения первой позиции μ + λ , для которой xμ + λ = xμ .
Алгоритм использует два указателя в заданной последовательности: один (черепаха) идёт по значениям xi , а другой (заяц) по значениям x2i . На каждом шаге алгоритма индекс i увеличивается на единицу, передвигая черепаху на один элемент вперёд, а зайца — на два элемента, после чего значения в этих точках сравниваются. Наименьшее значение i > 0 , для которого черепаха и заяц будут указывать на одинаковые значения, является искомым значением ν .
Следующая программа на языке Python показывает, каким образом идея может быть реализована.
Данный код получает доступ к последовательности лишь запоминанием и копированием указателей, вычислением функции и проверкой равенства. Таким образом, алгоритм является алгоритмом указателей. Алгоритм использует O(λ + μ) операций этих типов и O(1) памяти [7] .
Алгоритм Брента [ править | править код ]
Ричард Брент описал альтернативный алгоритм нахождения цикла, которому, подобно алгоритму черепахи и зайца, требуется лишь два указателя на последовательность [8] . Однако он основан на другом принципе — поиске наименьшей степени 2 i числа 2, которая больше как λ , так и μ .
Для i = 0, 1, 2, . , алгоритм сравнивает x2 i −1 со значениями последовательности вплоть до следующей степени двух, останавливая процесс, когда найдётся совпадение. Алгоритм имеет два преимущества по сравнению с алгоритмом черепахи и зайца: во-первых, он находит правильную длину λ цикла сразу и не требуется второй шаг для её определения, а во-вторых, на каждом шаге вызов функции f происходит только один раз, а не три раза [9] .
Следующая программа на языке Python более детально показывает, как эта техника работает.
Подобно алгоритму черепахи и зайца, этот алгоритм является алгоритмом указателей, использующим O(λ + μ) проверок и вызовов функций и памяти O(1) . Несложно показать, что число вызовов функции никогда не превзойдёт числа вызовов в алгоритме Флойда.
Брент утверждает, что в среднем его алгоритм работает примерно на 36 % быстрее алгоритма Флойда, и что он обгоняет ро-алгоритм Полларда примерно на 24 %. Он осуществил анализ среднего варианта [en] вероятностной версии алгоритма, в котором последовательность индексов, проходимых медленным указателем, не является степенью двойки, а является степенью двойки, умноженной на случайный коэффициент. Хотя основной целью его алгоритма была разложение числа на множители, Брент также обсуждает приложение алгоритма для проверки псевдослучайных генераторов [8] .
Время в обмен на память [ править | править код ]
Много авторов изучали техники для нахождения цикла, использующих большее количество памяти, чем у методов Флойда и Брента, но, зато, работающих быстрее. В общем случае эти методы запоминают некоторые ранее вычисленные значения последовательности и проверяют, не совпадает ли новое значение с одним из запомненных. Чтобы делать это быстро, обычно они используют хеш-таблицы или подобные структуры данных, а потому такие алгоритмы не являются алгоритмами указателей (в частности, обычно их нельзя приспособить к ро-алгоритму Полларда). Чем эти методы отличаются, так это способом определения, какие значения запоминать. Следуя Нивашу [10] , мы кратко рассмотрим эти техники.
- Брент [8] уже описывал вариации своей техники, в которых индексы запомненных значений последовательности являются степенями числа R , отличного от двух. При выборе R ближе к единице и, запоминая значения последовательности с индексами, близкими к последовательным степеням R , алгоритм нахождения цикла может использовать число вызовов функции, которое не превосходит произвольно малого множителя оптимального значения λ + μ[11][12] .
- Седжвик, Шиманьский и Яо [13] предложили метод, который использует M ячеек памяти и требует в худшем случае только ( λ + μ ) ( 1 + c M − 1 / 2 ) <displaystyle (lambda +mu )(1+cM^<-1/2>)>
вызовов функции с некоторой постоянной c , для которой она показала оптимальность. Техника использует числовой параметр d , запоминая в таблице только те позиции последовательности, которые кратны d . Таблица очищается, а значение d удваивается, если число запомненных значений слишком велико.
- Некоторые авторы описали методы отмеченных точек, которые запоминают в таблице значения функции, опираясь на критерии, использующие значения, а не индексы (как в методе Седжвика и др.). Например, могут запоминаться значения по модулю от некоторого числа d [14][15] . Более просто, Ниваш [10] приписывает Вудруфу предложение запоминать случайно выбранное предыдущее значение, делая подходящий случайный выбор на каждом шаге.
- Ниваш [10] описывает алгоритм, который не использует фиксированного количества памяти, но для которого ожидаемое количество используемой памяти (в предположении, что входная функция случайна) логарифмически зависит от длины последовательности. По этой технике элемент записывается в таблицу, если никакой предыдущий элемент не имеет меньшего значения. Как показал Ниваш, элементы в этой технике можно располагать в стеке, и каждое последующее значение нужно сравнивать только с элементом на вершине стека. Алгоритм прекращает работу, когда повторение элемента с меньшим значением найдено. Если использовать несколько стеков и случайную перестановку значений внутри каждого стека, получаем выигрыш в скорости за счёт памяти аналогично предыдущим алгоритмам. Однако даже версия алгоритма с одним стеком не является алгоритмом указателей, поскольку требуется знать, какое из значений меньше.
Любой алгоритм нахождения цикла, запоминающий максимум M значений из входной последовательности, должен сделать по меньшей мере ( λ + μ ) ( 1 + 1 M − 1 ) <displaystyle (lambda +mu )(1+<frac <1>>)>
Приложения [ править | править код ]
Нахождение цикла используется во многих приложениях.
- Определение длины цикла генератора псевдослучайных чисел является одной из мер его силы. Об этом приложении говорил Кнут при описании метода Флойда [3] . Брент [8] описал результат тестирования линейного конгруэнтного генератора. Период генератора оказался существенно меньше афишированного. Для более сложных генераторов последовательность значений, в которых находят цикл, может не представлять вывод генератора, а лишь его внутреннее состояние.
- Некоторые алгоритмы теории чисел опираются на нахождение цикла, включая ро-алгоритм Полларда для факторизации целых чисел [18] и связанный с ним алгоритм «кенгуру» для задачи дискретного логарифмирования[19] .
- В криптографии возможность найти два различных значения xμ−-1 и xλ+μ−-1, отображающихся некоторой криптографической функцией ƒ в одно и то же значение xμ, может говорить о слабости ƒ. Например, Кискатр и Делессаилле [15] применили алгоритмы нахождения цикла для поиска сообщения и пары ключей DES, которые отображают это сообщение в одно и то же зашифрованное значение. Калиски, Ривест и Шерман[en][20] также использовали алгоритмы нахождения цикла для атаки на DES. Техника может быть использована для поиска коллизий в криптографической хеш-функции[21] .
- Нахождение циклов может быть полезно как путь обнаружения бесконечных циклов в некоторых типах компьютерных программ[22] .
- Периодические конфигурации в моделировании клеточного автомата можно найти, применив алгоритмы нахождения цикла к последовательности состояний автомата [10] .
- Анализ формы[en]связных списков является техникой проверки корректности алгоритма, использующего эти структуры. Если узел в списке ссылается некорректно на более ранний узел в том же списке, структура образует цикл, который может быть найден с помощью таких алгоритмов [23] . В языке Common Lisp принтер S-выражений при переменной *print-circle* обнаруживает зацикленные списковые структуры и печатает их компактно.
- Теске [12] описывает приложение в вычислительной теории групп для вычисления структуры абелевой группы по множеству её генераторов. Криптографические алгоритмы Калиски и др. [20] можно рассматривать также как попытку раскрыть структуру неизвестной группы.
- Фич [24] коротко упомянула применение для компьютерного моделированиянебесной механики, которое она приписывает Кэхэну. В этом приложении нахождение цикла в фазововом пространстве системы орбит можно использовать для определения, является ли система периодической с точностью модели [16] .
| Задача: |
| Дан граф, требуется проверить наличие цикла в этом графе. |
Содержание
Алгоритм [ править ]
Будем решать задачу с помощью поиска в глубину.
В случае ориентированного графа произведём серию обходов. То есть из каждой вершины, в которую мы ещё ни разу не приходили, запустим поиск в глубину, который при входе в вершину будет красить её в серый цвет, а при выходе из нее — в чёрный. И, если алгоритм пытается пойти в серую вершину, то это означает, что цикл найден.
В случае неориентированного графа, одно ребро не должно встречаться в цикле дважды по определению. Поэтому необходимо дополнительно проверять, что текущее рассматриваемое из вершины ребро не являетя тем ребром, по которому мы пришли в эту вершину.
Заметим, что, если в графе есть вершины с петлями, то алгоритм будет работать корректно, так как при запуске поиска в глубину из такой вершины, найдется ребро, ведущее в нее же, а значит эта петля и будет являться циклом.
Для восстановления самого цикла достаточно при запуске поиска в глубину из очередной вершины добавлять эту вершину в стек. Когда поиск в глубину нашел вершину, которая лежит на цикле, будем последовательно вынимать вершины из стека, пока не встретим найденную еще раз. Все вынутые вершины будут лежать на искомом цикле.
Асимптотика поиска цикла совпадает с асимптотикой поиска в глубину — [math]O(|V| + |E|)[/math] .
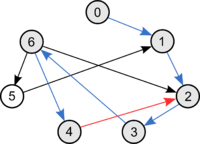
Доказательство [ править ]
Пусть дан граф [math]G[/math] . Запустим [math]mathrm
Докажем, что если в графе [math]G[/math] существует цикл, то [math]mathrm
